絡(luò)科技專注于整合策劃、平臺搭建、運營、營銷方案定制,電商類分銷、批發(fā)商城、小程序")

|
文章列表
|
11步構(gòu)建完整產(chǎn)品數(shù)據(jù)運營體系—來自騰訊、YY和迅雷的10年實踐 二維碼
127
發(fā)表時間:2017-05-17 21:45作者:蘭軍,BLUE 作者 / 蘭軍,BLUES,資深產(chǎn)品專家和運營專家,原騰訊和YY語音高級產(chǎn)品經(jīng)理,原迅雷產(chǎn)品總監(jiān),現(xiàn)為梅沙科技創(chuàng)始人。《運營策劃2》策劃人。 不少人對數(shù)據(jù)運營的理解,局限于數(shù)字統(tǒng)計、原因分析等,其實這些只是數(shù)據(jù)運營工作的一小部分,數(shù)據(jù)最終是為產(chǎn)品服務(wù)的,數(shù)據(jù)運營,重點在運營,數(shù)據(jù)只是工具。 數(shù)據(jù)運營是做什么的?個人的理解是: 制訂產(chǎn)品目標(biāo),創(chuàng)建數(shù)據(jù)上報通道和規(guī)則流程,觀測產(chǎn)品數(shù)據(jù),做好數(shù)據(jù)預(yù)警,分析數(shù)據(jù)變化原因,根據(jù)分析結(jié)果優(yōu)化產(chǎn)品和運營,并對未來數(shù)據(jù)走勢做出預(yù)測,為產(chǎn)品決策提供依據(jù),在產(chǎn)品策劃與運營中融入數(shù)據(jù)應(yīng)用。 通俗點說,數(shù)據(jù)運營搞清楚以下5個問題: l 我們要做什么?——目標(biāo)數(shù)據(jù)制訂; l 現(xiàn)狀是什么?——行業(yè)分析,產(chǎn)品數(shù)據(jù)報表輸出; l 數(shù)據(jù)變化的原因?——數(shù)據(jù)預(yù)警,數(shù)據(jù)變化的原因分析; l 未來會怎樣?——數(shù)據(jù)預(yù)測; l 我們應(yīng)該做什么?——決策與數(shù)據(jù)的產(chǎn)品應(yīng)用。 如何才能構(gòu)建一個完整的產(chǎn)品數(shù)據(jù)運營體系?Blues根據(jù)自己在YY工作的經(jīng)驗進行了梳理和總結(jié),整個過程可以分為如下的11步,供大家參考。
第1步:制訂產(chǎn)品目標(biāo) 這是數(shù)據(jù)運營的起點,也是產(chǎn)品上線運營后進行評估的標(biāo)準(zhǔn),以此形成閉環(huán)。制訂目標(biāo)絕不能拍腦袋,可以根據(jù)業(yè)務(wù)發(fā)展、行業(yè)發(fā)展、競品分析、往年產(chǎn)品發(fā)展走勢、產(chǎn)品轉(zhuǎn)化規(guī)律等綜合計算得出。制訂目標(biāo)常用SMART原則來衡量。 (1)S代表具體(Specific) 指工作指標(biāo)要具體可評,不能籠統(tǒng)。例如我們制定YY語音基礎(chǔ)體驗的產(chǎn)品目標(biāo),如果是提升產(chǎn)品體驗,則不夠具體,每個人的理解不一致,當(dāng)時我們的基礎(chǔ)產(chǎn)品目標(biāo)則是提升新用戶次日留存,則非常具體。 (2)M代表可度量(Measurable) 指績效指標(biāo)是數(shù)量化或者行為化的,驗證這些績效指標(biāo)的數(shù)據(jù)或者信息是可以獲得的;提升新用戶次日留存率,則需要給出具體的數(shù)值。 (3)A代表可實現(xiàn)(Attainable) 指績效指標(biāo)在付出努力的情況下可以實現(xiàn),避免設(shè)立過高或過低的目標(biāo);新注冊用戶的次日留存率,也不是拍腦袋得出的,當(dāng)時我們基于YY新用戶次日留存率的歷史數(shù)據(jù)和游戲用戶的新注冊用戶留存率的行業(yè)參考數(shù)值,制訂了一個相對有挑戰(zhàn)性的目標(biāo),從新注冊用戶次日留存率從25%提升到35%。 (4)R代表相關(guān)性(Relevant) 是與工作的其它目標(biāo)是相關(guān)聯(lián)的;績效指標(biāo)是與本職工作相關(guān)聯(lián)的;新用戶的次日留存率,和用戶行為息息相關(guān),例如用戶對語音工具的認可程度,用戶對YY平臺的內(nèi)容喜好程度等,所以新用戶的次日留存和產(chǎn)品的性能、內(nèi)容受歡迎程有較強的相關(guān)性。 (5)T代表有時限(Time-bound) 注重完成目標(biāo)的特定期限。 產(chǎn)品目標(biāo)可以這樣制訂:在2013年12月31日前,將YY語音新注冊用戶的次日留存率從25%提升到35%。 新用戶次日留存率的提升,意味著更多用戶的活躍轉(zhuǎn)化,帶動整個用戶活躍數(shù)量的增長。 第2步:定義產(chǎn)品數(shù)據(jù)指標(biāo) 產(chǎn)品數(shù)據(jù)指標(biāo)是反應(yīng)產(chǎn)品健康發(fā)展的具體的數(shù)值,我們需要對數(shù)據(jù)指標(biāo)給出明確定義,例如數(shù)據(jù)上報方法、計算公式等。 例如上文的次日留存率,可以定義為:次日留存率是一個比率,分母是當(dāng)天新注冊并在當(dāng)天登錄YY客戶端的YY帳戶數(shù),分子是分母當(dāng)中在第二天再次登錄YY客戶端的YY帳戶數(shù)。 注意這里的細節(jié),**天和第二天,需要有明確的時間點,例如0點到24點,計算為一天;問題來了,一個新用戶在**天的23點注冊并登錄YY客戶端,到第二天的凌晨1點下線;按照上面的定義,這個用戶或許將不會被記錄為次日留存用戶,因為這里沒有定義清楚數(shù)據(jù)上報細節(jié)。 定義是第二天再次登錄YY客戶端,上面案例的用戶在第二天是沒有登錄行為的,但他確實是連續(xù)兩天都在登錄狀態(tài)的用戶。 所以針對這個定義,需要補充細節(jié):用戶登錄狀態(tài),如果是5分鐘進行一次心跳包的上報,那么這位新用戶就可以被上報為第二天的登錄狀態(tài)用戶,如果在0點5分之前下線之后,持續(xù)到第二天的24點,仍未有登錄狀態(tài),那么將不被記錄為留存用戶。 我們根據(jù)產(chǎn)品目標(biāo)來選擇數(shù)據(jù)指標(biāo),例如網(wǎng)頁產(chǎn)品,經(jīng)常用PV、UV、崩失率、人均PV、停留時長等數(shù)據(jù)進行產(chǎn)品度量。定義產(chǎn)品指標(biāo)體系,需要產(chǎn)品、開發(fā)等各個團隊達成共識,數(shù)據(jù)指標(biāo)的定義是清晰的,并且有據(jù)可查,不會引起數(shù)據(jù)解讀的理解差異。 第3步:構(gòu)建產(chǎn)品數(shù)據(jù)指標(biāo)體系 在數(shù)據(jù)指標(biāo)提出的基礎(chǔ)上,我們按照產(chǎn)品邏輯進行指標(biāo)的歸納整理,使之條理化。 新用戶的次日留存率是我們訂制的一個核心目標(biāo),但實際上,只看次日留存率還是不夠的,還需要綜合考察影響用戶留存率的多種因素,才能更準(zhǔn)確的了解產(chǎn)品的健康發(fā)展。如圖1所示,是常用的一種指標(biāo)體系,包含:用戶新增、用戶活躍、付費、其他數(shù)據(jù)。
圖1 互聯(lián)網(wǎng)產(chǎn)品常用數(shù)據(jù)指標(biāo)體系
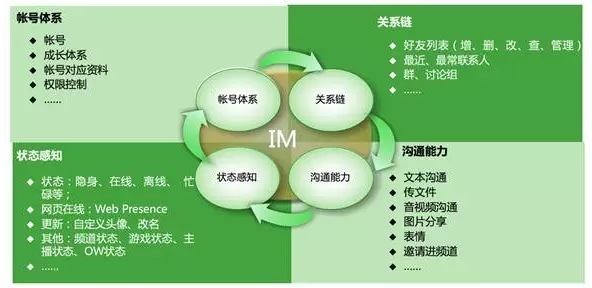
在我們做YY語音客戶端產(chǎn)品的時候,會用到下面的指標(biāo)體系,包括:賬號體系、關(guān)系鏈數(shù)據(jù)、狀態(tài)感知數(shù)據(jù)、溝通能力等四大方面。具體指標(biāo)有:好友的個數(shù)分布、觀看頻道節(jié)目的時長、IM聊天時長、個人狀態(tài)的切換與時長等,如圖2所示:
第4步:提出產(chǎn)品數(shù)據(jù)需求 產(chǎn)品指標(biāo)體系的建立不是一蹴而就的,產(chǎn)品經(jīng)理根據(jù)產(chǎn)品發(fā)展的不同階段,有所側(cè)重的進行數(shù)據(jù)需求的提出,一般的公司都會有產(chǎn)品需求文檔的模板,方便產(chǎn)品和數(shù)據(jù)上報開發(fā)、數(shù)據(jù)平臺等部門同事溝通,進行數(shù)據(jù)建設(shè)。創(chuàng)業(yè)型中小企業(yè),產(chǎn)品數(shù)據(jù)的需求提出到上報或許就是1-2人的事情,但同樣建議做好數(shù)據(jù)文檔的建設(shè),例如數(shù)據(jù)指標(biāo)的定義,數(shù)據(jù)計算邏輯等。 圖3是BLUES在YY語音客戶端團隊建立的基礎(chǔ)產(chǎn)品數(shù)據(jù)需求實現(xiàn)流程。
圖3 YY事業(yè)部基礎(chǔ)產(chǎn)品數(shù)據(jù)需求實現(xiàn)流程圖(施行)
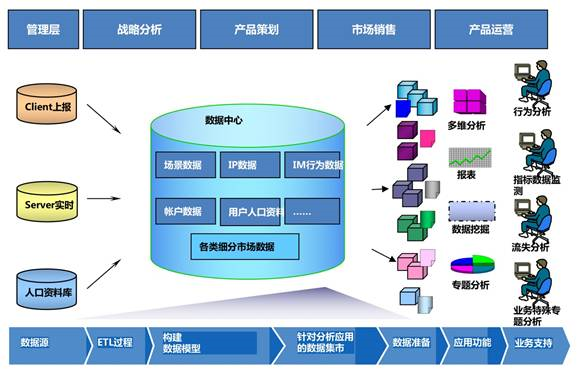
第5步:上報數(shù)據(jù) 這個步驟就是開發(fā)根據(jù)產(chǎn)品經(jīng)理的數(shù)據(jù)需求,按照數(shù)據(jù)上報規(guī)范,完成上報開發(fā),將數(shù)據(jù)上報到數(shù)據(jù)服務(wù)器。上報數(shù)據(jù)的關(guān)鍵是數(shù)據(jù)上報通道的建設(shè),原來在騰訊工作時候,沒有體會到這個環(huán)節(jié)的艱辛,因為數(shù)據(jù)平臺部門已經(jīng)做了完備的數(shù)據(jù)通道搭建,開發(fā)按照一定規(guī)則,使用統(tǒng)一的數(shù)據(jù)SDK進行數(shù)據(jù)上報就可以了。 后來在YY,屬于發(fā)展型公司,則是從上報通道開始進行建設(shè),也讓我得到更多鍛煉提升的機會。其中很關(guān)鍵的一個環(huán)節(jié),就是數(shù)據(jù)上報測試,曾經(jīng)因為該環(huán)節(jié)的測試資源沒到位,造成不必要的麻煩。 很多創(chuàng)業(yè)公司沒有自己的數(shù)據(jù)平臺,可以利用第三方的數(shù)據(jù)平臺:網(wǎng)頁產(chǎn)品,可以使用百度統(tǒng)計(tongji.baidu.com);移動端產(chǎn)品,可以使用友盟(www.umeng.com)、TalkingData(www.talkingdata.com)等平臺。 第6~8步:數(shù)據(jù)采集與接入、存儲、調(diào)度與運算 每一步都是一門學(xué)問,例如采集數(shù)據(jù)涉及接口創(chuàng)建,要考慮數(shù)據(jù)字段的拓展性,數(shù)據(jù)采集過程中的ETL數(shù)據(jù)清洗流程,客戶端數(shù)據(jù)上報的正確性校驗等;數(shù)據(jù)存儲與調(diào)度、運算,在大數(shù)據(jù)時代,更是很有挑戰(zhàn)性的技術(shù)活。 1.數(shù)據(jù)的采集與接入 ETL,是英文 Extract-Transform-Load 的縮寫,用來描述將數(shù)據(jù)從來源端經(jīng)過抽取(extract)、轉(zhuǎn)換(transform)、加載(load)至目的端的過程。ETL一詞較常用在數(shù)據(jù)倉庫,但其對象并不限于數(shù)據(jù)倉庫。ETL是構(gòu)建數(shù)據(jù)倉庫的重要一環(huán),用戶從數(shù)據(jù)源抽取出所需的數(shù)據(jù),經(jīng)過數(shù)據(jù)清洗,最終按照預(yù)先定義好的數(shù)據(jù)倉庫模型,將數(shù)據(jù)加載到數(shù)據(jù)倉庫中去。 下圖是產(chǎn)品數(shù)據(jù)體系的一個常見流程圖,數(shù)據(jù)采集、存儲、運算,通常就在圖中的數(shù)據(jù)中心完成。
確認完數(shù)據(jù)上報之后,接下來幾個事情就比較偏技術(shù)化了。首先需要上報的數(shù)據(jù)通過什么樣的方式采集和存儲到我們的數(shù)據(jù)中心。 數(shù)據(jù)采集分為兩步,**步從業(yè)務(wù)系統(tǒng)上報到服務(wù)器,這部分主要是通過cgi或者后臺server,通過統(tǒng)一的logAPI調(diào)用之后,匯總在logServer中進行原始流水?dāng)?shù)據(jù)的存儲。當(dāng)這部分?jǐn)?shù)據(jù)量大了之后,需要考慮用分布式的文件存儲來做,外部常用的分布式文件存儲主要是HDFS。這里就不細展開。
圖5 原始數(shù)據(jù)上報存儲到文件的架構(gòu)圖
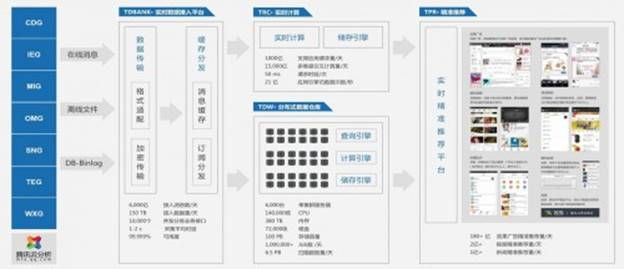
數(shù)據(jù)存儲到文件之后,第二步就進入到ETL的環(huán)節(jié),ETL就是指通過抽取(extract)、轉(zhuǎn)換(transform)、加載(load)把日志從文本中,基于分析的需求和數(shù)據(jù)緯度進行清洗,然后存儲在數(shù)據(jù)倉庫中。 以騰訊為例子:騰訊大數(shù)據(jù)平臺現(xiàn)在主要從離線和實時兩個方向支撐海量數(shù)據(jù)接入和處理,核心的系統(tǒng)包括TDW、TRC和TDbank。
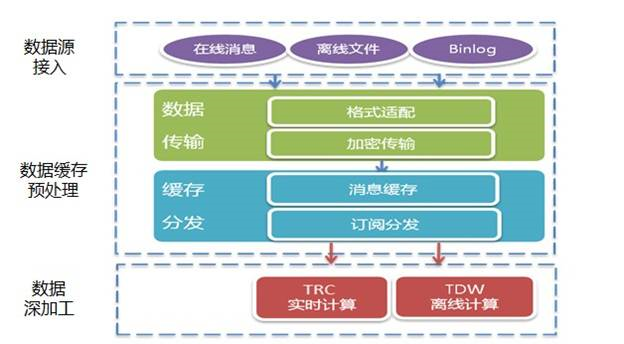
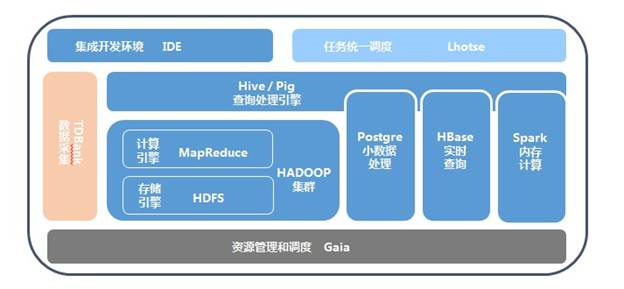
圖6 騰訊數(shù)據(jù)平臺系統(tǒng) 在騰訊內(nèi)部,數(shù)據(jù)的數(shù)據(jù)收集、分發(fā)、預(yù)處理和管理工作,都是通過一個TDBank的平臺來實現(xiàn)的。整個平臺主要解決在大數(shù)據(jù)量下面數(shù)據(jù)收集和處理的量大、實時、多樣的問題。通過數(shù)據(jù)接入層、處理層和存儲層這樣的三層架構(gòu)來統(tǒng)一解決接入和存儲的問題。 (1)接入層 接入層可以支持各種格式的業(yè)務(wù)數(shù)據(jù)和數(shù)據(jù)源,包括不同的DB、文件格式、消息數(shù)據(jù)等。數(shù)據(jù)接入層會將收集到的各種數(shù)據(jù)統(tǒng)一成一種內(nèi)部的數(shù)據(jù)協(xié)議,方便后續(xù)數(shù)據(jù)處理系統(tǒng)使用。 (2)處理層 接下來處理層用插件化的形式來支持多種形式的數(shù)據(jù)預(yù)處理過程。對于離線系統(tǒng)來說,一個重要的功能是將實時采集到的數(shù)據(jù)進行分類存儲,需要按照某些維度(比如某個key值+時間等維度)進行分類存儲;同時存儲文件的粒度(大小/時間)也是需要定制的,使離線系統(tǒng)能以指定的的粒度來進行離線計算。對于在線系統(tǒng)來說,常見的預(yù)處理過程如數(shù)據(jù)過濾、數(shù)據(jù)采樣和數(shù)據(jù)轉(zhuǎn)換等。 (3)數(shù)據(jù)存儲層 處理后的數(shù)據(jù),使用HDFS作為離線文件的存儲載體。保證數(shù)據(jù)存儲整體上是可靠的,然后最終把這部分處理后的數(shù)據(jù),入庫到騰訊內(nèi)部的分布式數(shù)據(jù)倉庫TDW。 圖7 TDW架構(gòu)圖 TDBank是從業(yè)務(wù)數(shù)據(jù)源端實時采集數(shù)據(jù),進行預(yù)處理和分布式消息緩存后,按照消息訂閱的方式,分發(fā)給后端的離線和在線處理系統(tǒng)。
圖8 TDBank數(shù)據(jù)采集與接入系統(tǒng) TDBank構(gòu)建數(shù)據(jù)源和數(shù)據(jù)處理系統(tǒng)間的橋梁,將數(shù)據(jù)處理系統(tǒng)同數(shù)據(jù)源解耦,為離線計算TDW和在線計算TRC平臺提供數(shù)據(jù)支持。目前通過不斷的改進,將以前Linux+HDFS的模式,轉(zhuǎn)變?yōu)榧?分布式消息隊列的模式,將以前一天才能處理的消息量縮短到2秒鐘! 從實際應(yīng)用來看,產(chǎn)品在考慮數(shù)據(jù)采集和接入的時候,主要要關(guān)心幾個緯度的問題 l 多個數(shù)據(jù)源的統(tǒng)一,一般實際的應(yīng)用過程中,都存在不同的數(shù)據(jù)格式來源,這個時候,采集和接入這部分,需要把這些數(shù)據(jù)源進行統(tǒng)一的轉(zhuǎn)化。 l 采集的實時高效,由于大部分系統(tǒng)都是在線系統(tǒng),對于數(shù)據(jù)采集的時效性要求會比較高。 l 臟數(shù)據(jù)處理,對于一些會影響整個分析統(tǒng)計的臟數(shù)據(jù),需要在接入層的時候進行邏輯屏蔽,避免后面統(tǒng)計分析和應(yīng)用的時候,由于這部分?jǐn)?shù)據(jù)導(dǎo)致很多不可預(yù)知的問題。
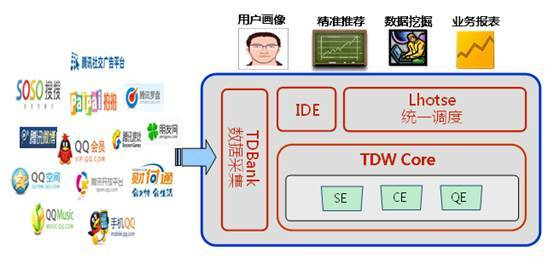
2.數(shù)據(jù)的存儲與計算 完成數(shù)據(jù)上報和采集和接入之后,數(shù)據(jù)就進入存儲的環(huán)節(jié),繼續(xù)以騰訊為例。 在騰訊內(nèi)部,有個分布式的數(shù)據(jù)倉庫用來存儲數(shù)據(jù),內(nèi)部代號叫做TDW,它支持百PB級數(shù)據(jù)的離線存儲和計算,為業(yè)務(wù)提供海量、高效、穩(wěn)定的大數(shù)據(jù)平臺支撐和決策支持。基于開源軟件Hadoop和Hive進行構(gòu)建,并且根據(jù)公司數(shù)據(jù)量大、計算復(fù)雜等特定情況進行了大量優(yōu)化和改造。 從對外公布的資料來看,TDW基于開源軟件hadoop和hive進行了大量優(yōu)化和改造,已成為騰訊**的離線數(shù)據(jù)處理平臺,集群各類機器總數(shù)5000臺,總存儲突破20PB,日均計算量超過500TB,覆蓋騰訊公司90%以上的業(yè)務(wù)產(chǎn)品,包含廣點通推薦,用戶畫像,數(shù)據(jù)挖掘和各類業(yè)務(wù)報表等,都是通過這個平臺來提供基礎(chǔ)能力。
圖9,騰訊TDW分布式數(shù)據(jù)倉庫
圖10 TDW業(yè)務(wù)示意圖
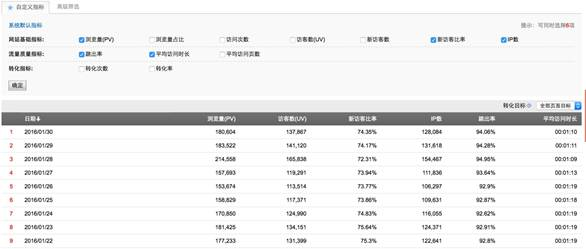
從實際應(yīng)用來看,數(shù)據(jù)存儲這部分主要考慮幾個問題: l 數(shù)據(jù)安全性,很多數(shù)據(jù)是不可恢復(fù)的,所以數(shù)據(jù)存儲的安全可靠永遠是最重要的。一定要投入最多的精力來關(guān)注。 l 數(shù)據(jù)計算和提取的效率,做為存儲源,后面會面臨很多數(shù)據(jù)查詢和提取分析的工作,這部分的效率需要確保。 l 數(shù)據(jù)一致性,存儲的數(shù)據(jù)主備要保證一致性。 第9步:獲取數(shù)據(jù) 就是產(chǎn)品經(jīng)理,數(shù)據(jù)分析人員從數(shù)據(jù)系統(tǒng)獲得數(shù)據(jù)的過程,常見的方式是數(shù)據(jù)報表和數(shù)據(jù)提取。 報表的格式,一般會在數(shù)據(jù)需求階段明確,尤其是有積累的公司,通常會有報表模板,照著填入指標(biāo)就好了。強大一些的數(shù)據(jù)平臺,則可以根據(jù)分析需要,自助的選擇字段(表頭)進行自助報表的配置和計算生成。 下面是做數(shù)據(jù)報表設(shè)計的幾個原則: 1.提供連續(xù)周期的查詢功能 (1)報表要提供查詢的起始時間,可以查看指定時間范圍內(nèi)的數(shù)據(jù)。忌諱只有一個時間點,無法看數(shù)據(jù)的趨勢。 (2)對一段時間范圍內(nèi)的數(shù)據(jù)能夠分段或匯總,能夠?qū)Σ煌A段進行比較。 2.查詢條件與維度相匹配 (1)有多少個維度,就提供多少個對應(yīng)的查詢條件。盡量滿足每個維度都能分析。 (2)查詢條件要提供開、合,以及具體值的過濾功能。既能看總體,又能看明細,還要能看單一。 (3)查詢條件的順序,盡量與維度的順序?qū)?yīng),**按從大到小的層次。 3. 圖表與數(shù)據(jù)要一致 (1)圖表顯示的趨勢,要與相應(yīng)的數(shù)據(jù)一致,避免數(shù)據(jù)有異議; (2)有圖就必須有數(shù)據(jù),但是,有數(shù)據(jù)可以沒有圖; (3)圖表內(nèi)的指標(biāo)不要太多,并且指標(biāo)間的差距不要太大。 4. 報表要單一 (1)一張報表,只做一份分析功能,多個功能盡量拆到不同的表報中; (2)在報表中盡量不要有跳轉(zhuǎn); (3)報表只提供查詢功能。 看幾張常用報表,WEB產(chǎn)品的流量報表,來自百度,關(guān)注PV、UV、新訪客比率、跳出率、平均訪問時長等。 專門說一下跳出率,這個數(shù)據(jù)反應(yīng)了用戶進入網(wǎng)站的著陸頁(不一定是首頁)價值,是否可以吸引用戶進行一次點擊,如果用戶達到著陸頁,沒有任何點擊,則跳出率增大。
圖11 百度統(tǒng)計的網(wǎng)頁數(shù)據(jù)報表
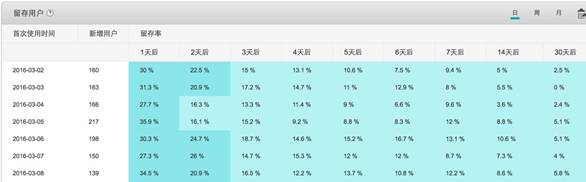
再看友盟數(shù)據(jù)平臺提供的產(chǎn)品留存率數(shù)據(jù)報表,通常關(guān)注的留存率有:1天后留存、7天后留存、30天后留存。
圖12 友盟的留存數(shù)據(jù)報表
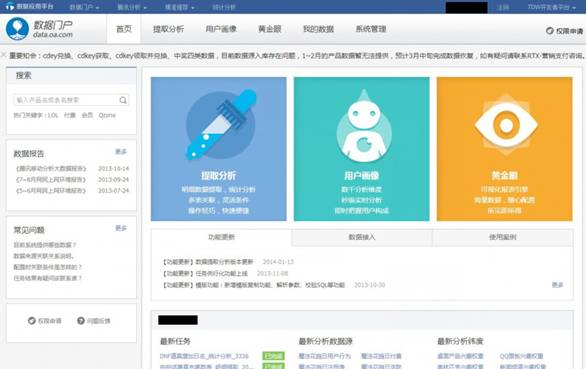
數(shù)據(jù)提取,在做產(chǎn)品運營中,是很常見的需求,例如提取某一批銷量較好的商品及其相關(guān)字段,提取某一批指定條件的用戶等。同樣,功能比較完備的數(shù)據(jù)平臺,會有數(shù)據(jù)自助提取系統(tǒng),不能滿足自助需求,則需要數(shù)據(jù)開發(fā)寫腳本進行數(shù)據(jù)提取。 圖12所示,騰訊內(nèi)部的數(shù)據(jù)門戶,承擔(dān)了諸多產(chǎn)品的數(shù)據(jù)報表、數(shù)據(jù)提取、數(shù)據(jù)報告的功能。
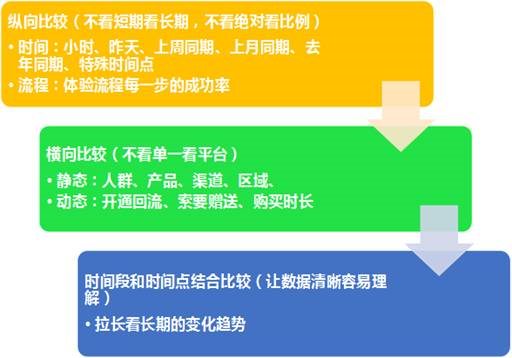
圖13 騰訊數(shù)據(jù)門戶首頁 第10步:觀測和分析數(shù)據(jù) 這里主要是數(shù)據(jù)變化的監(jiān)控和統(tǒng)計分析,通常我們會對數(shù)據(jù)進行自動化的日報表輸出,并標(biāo)識異動數(shù)據(jù),數(shù)據(jù)的可視化輸出很重要。 常用的軟件是EXCEL和SPSS,可以說是進行數(shù)據(jù)分析的基本技能,以后再分享個人在實際工作中對這兩款軟件的使用方法和技巧。需要注意的是,在進行數(shù)據(jù)分析之前,先進行數(shù)據(jù)準(zhǔn)確性的校驗,判斷這些數(shù)據(jù)是否是你想要的,例如從數(shù)據(jù)定義到上報邏輯,是否嚴(yán)格按照需求文檔進行,數(shù)據(jù)的上報通道是否會有數(shù)據(jù)丟包的可能,建議進行原始數(shù)據(jù)的提取抽樣分析判斷數(shù)據(jù)準(zhǔn)確性。 數(shù)據(jù)解讀在這個環(huán)節(jié)至關(guān)重要,同一份數(shù)據(jù),由于產(chǎn)品熟悉度和分析經(jīng)驗的差異,解讀結(jié)果也大不一樣,因此產(chǎn)品分析人員,必須對產(chǎn)品和用戶相當(dāng)了解。 絕對數(shù)值通常難以進行數(shù)據(jù)解讀,通常都是通過比較,才更能表達數(shù)據(jù)含義。 例如某產(chǎn)品上線后的**周,日均新增注冊10萬人,看起來數(shù)據(jù)不錯,但是如果這款產(chǎn)品是YY語音推出的新產(chǎn)品,并且通過YY彈窗消息進行用戶觸達,每天千萬次的用戶曝光,僅僅帶來10萬新增,則算不上是較好的產(chǎn)品數(shù)據(jù)。
圖13 通過比較更清晰表達數(shù)據(jù)含義 縱向比較,例如分析YY語音新注冊用戶的數(shù)據(jù)變化,那么可以和上周同期、上月同期、去年同期進行對比,是否有相似的數(shù)據(jù)變化規(guī)律。 橫向比較,同樣是YY語音新用戶注冊數(shù)據(jù)的變化,可以從漏斗模型進行分析,從用戶來源的不同渠道去看每個渠道的轉(zhuǎn)化率是否有變化,例如最上層漏斗,用戶觸達渠道有無哪個數(shù)據(jù)有較大變化,哪個渠道的某個環(huán)節(jié)有轉(zhuǎn)化率的數(shù)據(jù)變化。還可以進行不同業(yè)務(wù)的橫向比較,例如YY語音新增注冊數(shù)據(jù)、多玩網(wǎng)流量數(shù)據(jù)、YY游戲新增注冊用戶數(shù)據(jù)進行對比,查找數(shù)據(jù)變化原因。 縱橫結(jié)合對比,就是把多個數(shù)據(jù)變化的同一周期時間段曲線進行對比,例如YY新增注冊用戶、多玩網(wǎng)的流量數(shù)據(jù)、YY游戲新增注冊用戶的半年數(shù)據(jù)變化,三條曲線同時進行對比,找出某個數(shù)據(jù)異常的關(guān)鍵節(jié)點,再查找運營日志,看看有無運營活動的組織、有無外部事件的影響、有無特殊日子的影響因素。 第11步:產(chǎn)品評估與數(shù)據(jù)應(yīng)用 這是數(shù)據(jù)運營閉環(huán)的終點,同時也是新的起點,數(shù)據(jù)報表絕不是擺設(shè),也不是應(yīng)付領(lǐng)導(dǎo)的提問,而是切實的為產(chǎn)品優(yōu)化和運營的開展服務(wù),正如產(chǎn)品人員的績效,不僅僅是看產(chǎn)品項目是否按時完成,按時發(fā)布,更是要持續(xù)進行產(chǎn)品數(shù)據(jù)的觀測分析,評估產(chǎn)品健康度,同時將積累的數(shù)據(jù)應(yīng)用到產(chǎn)品設(shè)計和運營環(huán)節(jié)。 例如亞馬遜的個性化推薦產(chǎn)品,例如QQ音樂的猜你喜歡,例如淘寶的時光機,例如今日頭條的推薦閱讀等等。數(shù)據(jù)產(chǎn)品應(yīng)用,大致可以分為以下幾類: (1)以效果廣告為代表的精準(zhǔn)營銷 推薦周期短,實時性要求高;用戶短期興趣和即時行為影響力大;投放場景上下文和訪問人群特性。 產(chǎn)品案例:谷歌、Facebook、微信朋友圈。 (2)以視頻推薦為代表的內(nèi)容推薦 長期興趣的累積影響力大;時段和熱點事件;多維度內(nèi)容相關(guān)性很重要。 產(chǎn)品案例:Youtube (3)以電商推薦為代表的購物推薦 長期+短期興趣+即時行為綜合;最貼近現(xiàn)實,季節(jié)與用戶生活信息很關(guān)鍵;追求下單與成交,支付相關(guān)。 產(chǎn)品案例:亞馬遜、淘寶、京東。
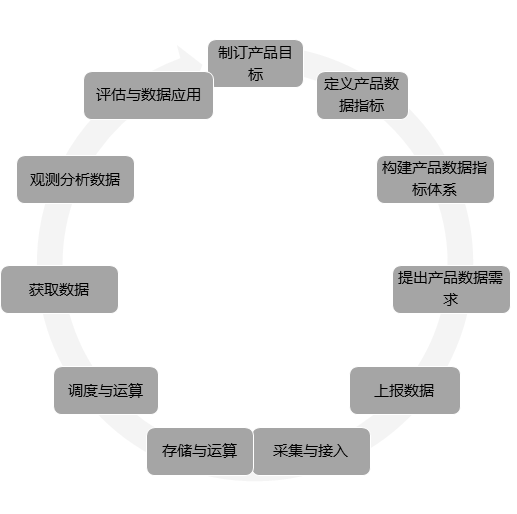
最后,一張圖小結(jié)數(shù)據(jù)運營11步:
圖14 數(shù)據(jù)運營11步 從制訂產(chǎn)品目標(biāo)到最后基于目標(biāo)進行產(chǎn)品評估與運營優(yōu)化,形成數(shù)據(jù)運營閉環(huán)。這個流程和規(guī)范,需要各個部門都能統(tǒng)一意識,每個產(chǎn)品終端都能按照規(guī)范流程將數(shù)據(jù)統(tǒng)一上報,建立公司級的統(tǒng)一數(shù)據(jù)中心,進行數(shù)據(jù)倉庫建設(shè),才有可能將數(shù)據(jù)價值**化,讓數(shù)據(jù)成為生產(chǎn)力。 產(chǎn)品數(shù)據(jù)運營體系如何構(gòu)建?可以從以下五大要素進行考慮: (1)人:專職的數(shù)據(jù)運營同事 專職的專業(yè)的產(chǎn)品同事,負責(zé)建立產(chǎn)品數(shù)據(jù)體系的流程化、標(biāo)準(zhǔn)化,沉淀經(jīng)驗,推動體系的持續(xù)優(yōu)化發(fā)展;專職的專業(yè)的開發(fā)同事,負責(zé)數(shù)據(jù)上報,報表開發(fā),數(shù)據(jù)庫開發(fā)維護等工作,保證產(chǎn)品數(shù)據(jù)體系的開發(fā)實現(xiàn); (2)數(shù)據(jù)后臺:全面系統(tǒng)的數(shù)據(jù)倉庫 有一個專門的統(tǒng)一數(shù)據(jù)倉庫記錄自己產(chǎn)品的特殊個性數(shù)據(jù),共性數(shù)據(jù)充分利用數(shù)據(jù)平臺部公用接口獲取,共享數(shù)據(jù)源,充分降低成本。 (3)數(shù)據(jù)前臺:固化數(shù)據(jù)體系展現(xiàn)平臺 需要專業(yè)的報表開發(fā)同事, 體系化思考報表系統(tǒng),靈活迭代執(zhí)行,而不是簡單的承接報表需求,造成報表泛濫。 (4)工作規(guī)范:需求實現(xiàn)流程化 就是前面描述的11步構(gòu)建產(chǎn)品數(shù)據(jù)體系的流程和方法,其中的數(shù)據(jù)需求把握好兩點,一是固化需求開發(fā)流程化,二是臨時需求工具化。 (5)工作產(chǎn)出:數(shù)據(jù)應(yīng)用 常規(guī)的數(shù)據(jù)工作就是各種數(shù)據(jù)分析,輸出日報、周報、月報;基于數(shù)據(jù)分析基礎(chǔ)上進行決策依據(jù)提供。進行數(shù)據(jù)產(chǎn)品開發(fā),例如精準(zhǔn)推薦、用戶生命周期管理等產(chǎn)品策劃。 |